- The Two Basic Kinds of Fonts: Outline and Bitmapped
- What's in a Font?
- Cross-Platform Font-Compatibility Issues
- Finding the Characters You Need
- Identifying Font Formats
- The Basics of Font Management
- Font-Editing Programs
This chapter is from the book
This chapter is from the book
This chapter is from the book
Cross-Platform Font-Compatibility Issues
The legacy left by evolving font standards continues to bedevil the movement of document files between different computer systems. The only way to be sure that a typeset document appears on one platform exactly as it was designed on another platform is to create it using the same OpenType fonts from the same vendor on both platforms.
Font-Encoding Issues
How numbers are assigned to the characters within a typeface is referred to as a font's encoding. Before they supported Unicode, the Macintosh and Windows operating systems used different encoding schemes.
Not only did the pre-Unicode operating systems use different character-numbering schemes, but they also used different subsets of the basic Latin 1 character collection as their standard character sets. The Macintosh set and encoding scheme were called MacRoman; the Windows character set and encoding scheme were called Win ANSI. Although a vendor might sell identical fonts for both platforms, the Mac would allow its users to access one group of characters within a font, and Windows another. Figure 4.6 shows the characters that were unique to each platform.
)
Figure 4.6 Of the basic PostScript Type 1 character set shown in , only Windows programs have direct keyboard access to the group of characters shown at the top here. Only Macintosh programs can use the keyboard to access the ones in the middle group. The bottom group includes characters in the basic MacRoman encoding that appear to be in every Mac font, but they are actually borrowed from the Symbol font.
Today's operating systems on both platforms allow access to all of these characters. But both the Mac and PC lack keystroke combinations that allow you to easily type their formerly inaccessible characters. For the sake of backward compatibility, and in respect for people's keyboarding habits, both operating systems act as if their old encoding schemes were still in use. To get access to the Unicode characters, you have to use special techniques (discussed in the next section).
Although Unicode is not a font encoding per se, it does provide applications on any platform with a standard way of indicating which characters to use. To assure the accurate representation of text as it travels through other computer systems, using Unicode-based fonts is a must.
Footnote: The Mac's "Borrowed Characters"
When you're working with PostScript fonts (and many TrueType fonts) on a Macintosh, the MacRoman encoding borrows certain characters from the Symbol font (see Figure 4.6). Such characters seem to be a part of every font you use. The keystroke combination Option-D, for example, always yields a lowercase Greek delta: 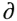 . But the numbers assigned to these characters in the MacRoman encoding scheme point to blank "slots" in a Mac font. Calls for these numbers are diverted by the operating system to the Symbol font. That explains why these characters never match the style of the typeface you're working in (unless it happens to be Times Roman, upon whose design the seriffed Symbol characters are based).
. But the numbers assigned to these characters in the MacRoman encoding scheme point to blank "slots" in a Mac font. Calls for these numbers are diverted by the operating system to the Symbol font. That explains why these characters never match the style of the typeface you're working in (unless it happens to be Times Roman, upon whose design the seriffed Symbol characters are based).
This curious situation is unique to the Mac and unique to this small handful of characters. It's been largely corrected in most OpenType equivalents of older PostScript fonts through the incorporation of these formerly borrowed characters into their expanded character sets. The Mac OS now explicitly shows that it's using the Symbol font when you use the original keyboard commands to set these characters.